





Digital giants such as FAANG—Facebook, Amazon, Apple, Netflix, and Google—and Microsoft have found business experimentation to be a game changer for optimizing investments and costs. Across their organizations, from marketing to product to engineering to media, these companies run thousands of experiments that have collectively boosted revenue by upwards of 10% annually. Not only tech majors have benefited from the recent rise in business experimentation. A recent study of over 35,000 startups found that companies implementing A/B testing showed a 5-15% increase in website visits and positive correlations with increased product introductions, code changes, and other performance metrics.1 Firms without digital roots and larger brick-and-mortar retailers—including FedEx, Target, and Walmart—have also turned to experimentation in recent years to classify digital touchpoints and optimize features such as design choices, discounts, and product recommendations. Further, in the offline world, experiments focused on planogram product mix changes, employee work shift scheduling,distribution center routines, and omni channel loyalty programs are consistently subjected to rigorous testing methods to drive innovation and growth while optimizing costs.
In the digital economies of today, rapidly changing competitive landscapes and customer expectations require organizations to respond with agility and speed. This, in turn, requires that organizations are able to assess business models, product development, pricing strategies, marketing campaigns, and a host of other processes on the strength of scientific, evidence-based criteria, rather than intuitive reactions.
Why experiments are vital to businesses
Why don’t more companies conduct rigorous tests of risky and expensive transitions and overhauls? Most organizations are reluctant to fund sufficiently rigorous business experiments and face considerable difficulty in executing them due to a lack of meaningful tooling and methodology (more on this later in this article). Although the process of experimentation seems straightforward, it can be surprisingly difficult in practice, owing to myriad organizational and technical challenges. That is the overarching conclusion we draw from our over 50 years of collective experience conducting and studying business experiments at dozens of companies, including eBay, Target, Paypal, PayU, Groupon, Yahoo and the like.
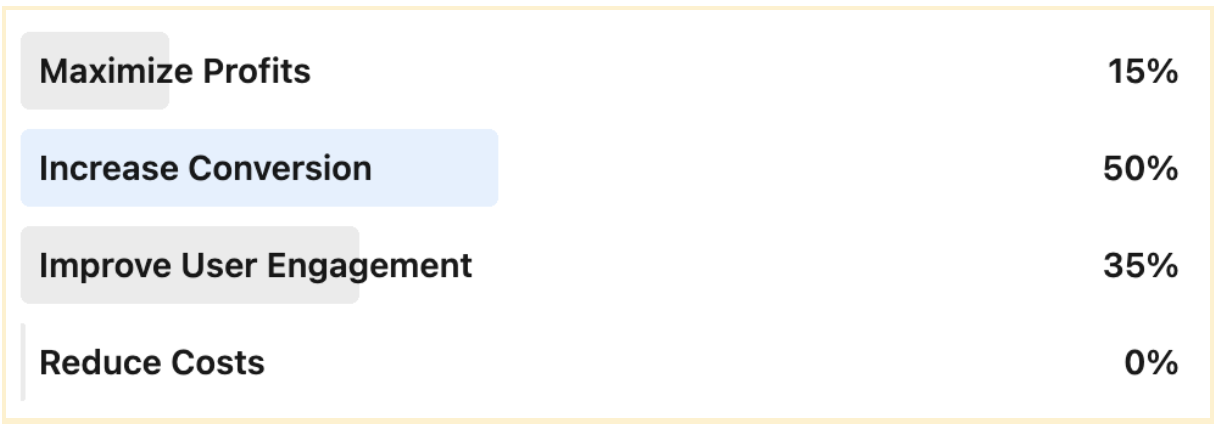
Companies also struggle with defining Success Criteria or Overall Evaluation Criteria (OEC). Below are the results of a survey of global leaders of Fortune 500 companies on this topic, which show a wide distribution of success criteria.
What is your primary Overall Evaluation Criteria(OEC) for your experiments today? 2
At first glance, observational methods might seem an easy shortcut to the myriad difficulties of experimentation. However, observations only give us correlation, not causation. In other words, we can only say that two events occurred together, not that one caused the other. Observational methods are further impacted by the fact that observed users/customers tend etitive landscapes and customer expectations require organizations to respond with agilitto act differently when observed. Survey people on a social issue, for instance, and you often get responses that they feel society expects them to give. Finding a subset of people or sample that is representative enough of the general population is an expensive and time-consuming exercise as well. Finally, observational studies are often at risk of erroneous conclusions due to unobserved factors that may be producing the observed result.
These factors explain the importance of experiments, which resolve the unknowns of observational studies by controlling the operation of different factors as well as how the sample is exposed to the conditions of the experiment. Because the operation of different factors is more strictly controlled, experiments can make claims of causation instead of mere correlation. Experiments also minimize bias by randomly assigning different members of the study sample to either be exposed to the changing conditions or treatment or not. Finally, while observational studies require theories to identify factors and decipher what changes in them mean, experiments can be designed and deployed without a prior theoretical explanation.
Types of Experiments
Not all experiments are equal when it comes to establishing causality. This is not the only design criterion that decides the quality or value of an experiment, since there are situations in which the level of evidence is reduced in order to accommodate other criteria. In terms of the level of evidence required to prove a hypothesis, however, experiments can be divided into:
1) True or randomized experiments
True or randomized experiments are considered the gold standard for inferring causality. In this design, subjects are randomly assigned to either receive the treatment or be in the control group that experiences no change in conditions. When testing how the colour of the sign-up button affects sign-ups for instance, experimenters will randomly change the colour of the button for half of users across geographies, interfaces/browsers, and so on. This ensures that all differences between users average out across the sample. In the process, the influence of any of those differences on the observed change in performance is eliminated. Thus, experimenters can say with confidence, for example, that the colour of the sign-up button directly affected sign-up rates because none of the other factors formed significant differences between the treatment and control groups.
2) Adaptive experimental designs
Sometimes, running the full range of experiments to achieve sufficient confidence in predictions of causality can take more time and effort than a company can afford. Adaptive experimental designs can drastically speed up this process by making mid-experiment changes to how subjects are assigned to different control and treatment conditions. This ensures that sufficient subjects experience the optimal treatment in fewer trials. Such designs are useful because they ensure that users or stakeholders are not needlessly subjected to sub-optimal treatments or conditions for longer periods of time. The biggest challenge of adaptive designs is to ensure that the mid-experiment changes do not in any way introduce researcher interference or bias towards one or the other treatment measure.
3) Quasi-experiments
While randomized experiments yield the highest confidence in terms of causality, it may often be impossible or impractical to randomize test subjects in this way. For instance, when testing the effects of a mass media advertising campaign, companies cannot decide who is or is not exposed to the advertising. Similarly, if users’ eligibility for a new feature is decided by a range of other factors, it may not be possible to randomize across all of these. In such cases, quasi-experiments can be deployed. Quasi-experiments deploy all of the conditions of random experiments to minimize the effects of confounding variables and to clearly establish the direction of causality from the treatment to the effect. However, they differ crucially in that the treatment and control groups are defined by one or more factor that the experimenters do not control. In order to make up for this shortfall, experimenters use a variety of statistical methods to ensure that existing differences between the groups are accounted for, so that their effect on the outcome of the experiment is not spuriously attributed to the factor under study. While the confidence with which these studies can confirm causation is lower than randomized studies, they do adhere more closely to real-world conditions than the latter.
4) Counterfactuals
In some cases, organizations may not have the time or resources to undertake randomized or quasi-experiments by creating treatment and control groups for comparison. For instance, a company may need to release an urgent update that resolves a design glitch or bug but may also affect user experience. In such a case, experimenters can deploy a counterfactual design. Here, rather than relying on a control group, experimenters model a hypothetical control condition, statistically estimating what would have happened if the new feature had not been released. This requires a strong model that the experimenters can be absolutely confident of, without which the comparison could go awry. That is, the robustness of this model turns on the quality of the counterfactual prediction.
A/B testing vs Multivariate and factorial designs
Besides the allocation of subjects, the manner in which treatments are designed is also important. The most commonly followed design is called A/B Testing, where an experiment tests the impact of a single parameter. In a typical A/B test, subjects are exposed to one of two options differing in only one detail, and the outcome is measured in terms of a simple increase or decrease in value. This ensures that the results of experiments are not confounded by combinations of different factors. Simple and straightforward as they are, A/B tests are also limited in how much information can be gleaned in a single experiment. Thus, testing for combinations of factors can be expensive and time-consuming.
Multivariate testing solves some of these problems by testing combinations of multiple factors. This reduces the time and cost of experiments, as fewer trials are needed to test all the factors. However, one major obstacle to multivariate testing is having enough subjects to test each combination in a statistically significant manner.
Finally, factorial designs go further than multivariate designs by choosing certain significant combinations for testing, rather than requiring that all combinations of factors be tested.
Summary
Causal inferences are vital to an experimenter’s arsenal. However, experiments have to be adjusted to the demands of concrete situations and fine-tuned to the art of the possible. Thus, experimenters must rely on a variety of experimental designs to find their answers.
At the organizational level, realizing the transformative power of experimentation requires a sustained commitment. The more experiments you run, the more large, medium, and small changes that collectively generate significant benefits can be realized. Leveraging the right tools and using the right methodologies are essential to make experimentation a way of life for your business.


